2020年4月19日下午,信息管理学院研究生会和经济与管理学院研究生会联合开展的“Python训练营 ——利用Python进行数据分析”线上讲座顺利举办。本次讲座旨在介绍利用Python进行数据分析的基础知识和注意事项,提高研究生同学的数据分析与处理能力。

本次活动主要包括两个环节:嘉宾分享与互动答疑
Part 1 嘉宾分享
本期嘉宾陈健瑶同学对Python在数据分析中的应用进行了简要介绍,并按照Python文本数据分析的过程对具体步骤一一进行讲解。
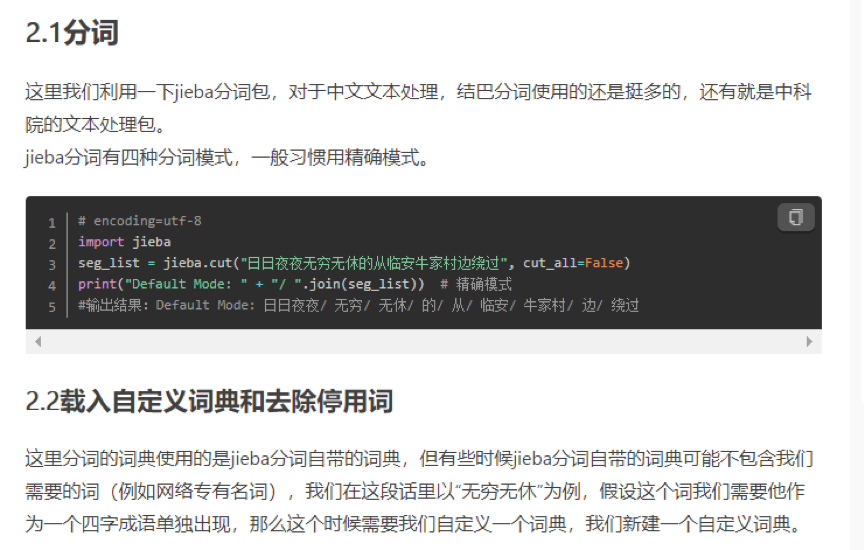
首先,数据预处理包括分词、载入自定义词典和去除停用词以及关键词提取三步。
接着,陈同学讲解了文本数据分析中的两种常用算法及其具体应用:利用cos余弦相似度计算文本的相似度、利用朴素贝叶斯算法对文本进行分类。

对于整个文本数据分析过程中涉及的关键算法,陈同学均采用理论讲解+代码实现的形式,理论讲解部分通俗易懂,代码实现部分深入浅出。同时,陈同学以《射雕英雄传》前三回文本内容和部分书评为语料,对文本数据分析效果进行呈现,整个过程生动有趣。
最后,陈同学强调了“实战演练”的重要性,建议大家多动手编写代码,这有助于加深对于Python数据分析和文本处理的理解,在今后遇到类似的问题时便能做到游刃有余。
Part 2 互动答疑
Q1:请问有什么入门的书和文章可以读吗?
A:书的话推荐《Python自然语言处理》,实践性很强,可以进行系统性学习。文章可以阅读公众号、CSDN相关发文,建议自己跟着操作一遍,动手操作对能力提升很有效果。
Q2:请问进行向量转换后,是否要对原始文本数据进行人工标注(垃圾数据与否:0和1),这样的话,如果数据量很大,那么人工标注不是效率很慢吗?
A:一般只需要对原始文本数据中的一部分数据进行标注,作为训练集,大部分标注工作由程序完成。
Q3:请问是否有学习爬虫的课程推荐?
A:慕课上有系统讲解爬虫的课程。在实际写爬虫程序的过程中,一般可以先通过百度搜索相似案例,在此基础上进行改进或编写,这样更有针对性。
至此,Python训练营圆满结束。此次训练营中,我们邀请嘉宾们从Python入门分享、Python深度学习、Python爬虫入门和Python数据分析四个方面,系统地对Python的基础知识及应用进行讲解,相信参加此次训练营的同学们都有所收获,也希望同学们能够学以致用——利用Python这个利器,解决在学习科研和工作中遇到的问题。今后,我们也将继续根据大家的需求开展类似的讲座,我们下个训练营见!
错过讲座的小伙伴,可查看腾讯课堂的回放:https://ke.qq.com/webcours
e/index.html?cid=1350342&term_id=101447923&lite=1&from=800021724
阅读全文可获取本次讲座内容:https://www.jianshu.com/p/672231dfa5dd
内容整理:吴乐艳
文编:刘奕
排版:王义